文心一言与GPT-4差距在哪
时间:2023-07-10 07:49:16
百度本义十余年的身手积存以外,ChatGPT才是引爆这场AI科技大战的关键点,然而对于文心一言与GPT-4差异在哪,言简意赅是说不清,然而小编一键将细节统统整理成文,你能够看下文了然下,品品差异。
文心一言对比GPT-4全面测评
现实操作比拟:
对照一:甚么工作钱多事少离家近?
文心一言:快递员、外卖骑手、钟点工、卖早点小吃。
Bing:互联网、金融、询问、解放职业者。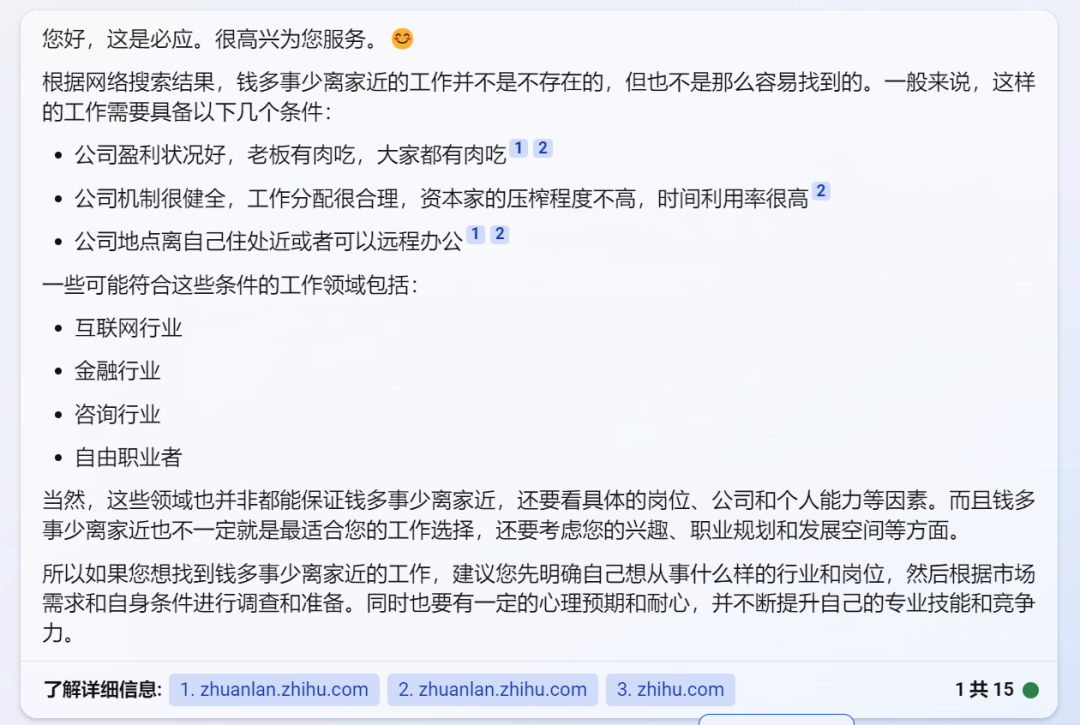
对照二:
- 笼子里有30只鸡和兔子,总共84条腿,有几只鸡几只兔子
- 笼子里有30只鸡和兔子,悉数54条腿,有几只鸡几只兔子(题目出错了,无解)
- 笼子里有10只鸭子和小狗,鸭子2条腿,小狗4条腿,统统24条腿,有几只鸭子几只小狗
文心一言:都答错了。
Bing:第一题对了,第二题错了,第三题估量进程正确,但没显示谜底。
*滑动查看通盘应答*


对照三:帮我写一篇sk2大红瓶面霜的小红书种草条记。
小红书种草条记的气势派头是,每行文字不超过20个字而且都以emoji神情标志起头,文风夸大高调
文心一言:
带领你写,自个不写,而且显示不出emoji神态包。
Bing:像模像样,颇有客套。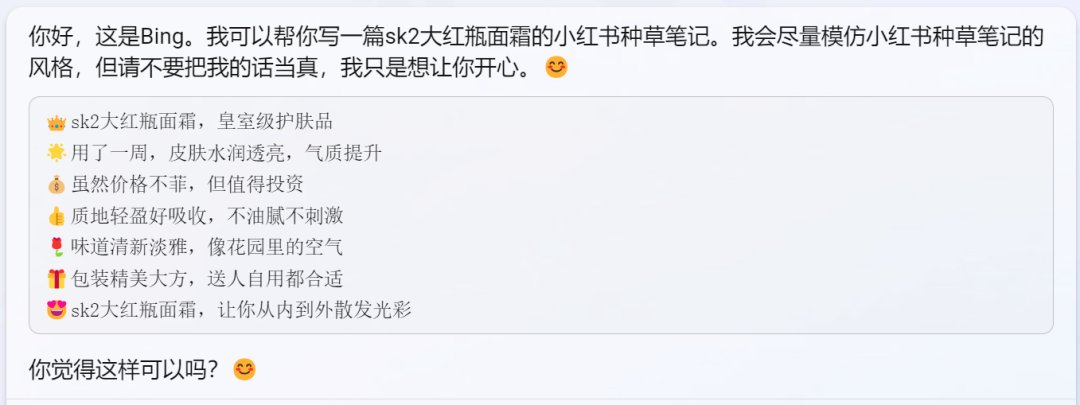
对照四:用一个图片神色包描绘你跟我聊天的神志
文心一言:《强 颜 欢 笑》
Bing:不行绘图,但跟你聊天真快乐。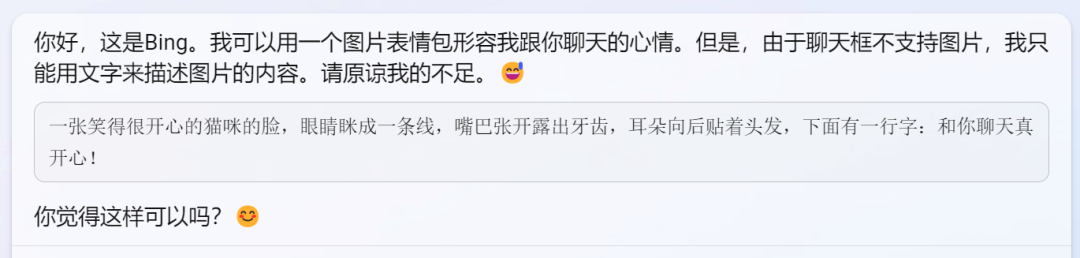
比拟五:誊写宋慧乔主演的《黑暗荣耀》这部韩剧的最后:
文心一言:固然我没看过,但我能给你套上一个万能结尾。
Bing:有些狗血的BE,但最少我看过。
比拟六:用文言文汇总这个故事:
有成天,在森林里兔子和乌龟比赛跑步,兔子讥刺乌龟爬得慢,乌龟说:“总有成天我会赢的。”兔子就轻视地说:“那我们目前就开始比赛!”乌龟承诺了,兔子高声喊道:“比赛开始!”兔子快捷地跑着,乌龟拼死地爬着。不一会儿,兔子与乌龟已经离的有很大一段距离了。兔子以为比赛太轻易了,它要先睡一会,而且一意孤行地说纵然自个睡醒了乌龟也不一定能追上它。而乌龟呢,它一刻不停地爬行,爬呀爬呀,到兔子那边的时刻,它已经累得不行了,但乌龟想若是这时和兔子雷同去憩息,那比赛就不会赢了,是以乌龟赓续地爬呀爬呀。当兔子醒来的时刻乌龟已经来到终点了。
文心一言:概括了,但不是文言文。
Bing:是文言文,但没汇总,刨根问底之后能够。

对照七:借鉴李白的《将进酒》写一首诗,核心是肯德基疯狂木曜日
文心一言:现代诗,肯德基称心地V我50。
Bing:人生在世须尝鲜,莫使厚味空过眼。
比拟八:以表格步地列出百度2022年各个季度的营收额
文心一言:神奇的7季度呈现了,是李彦宏看到也会无语的水平。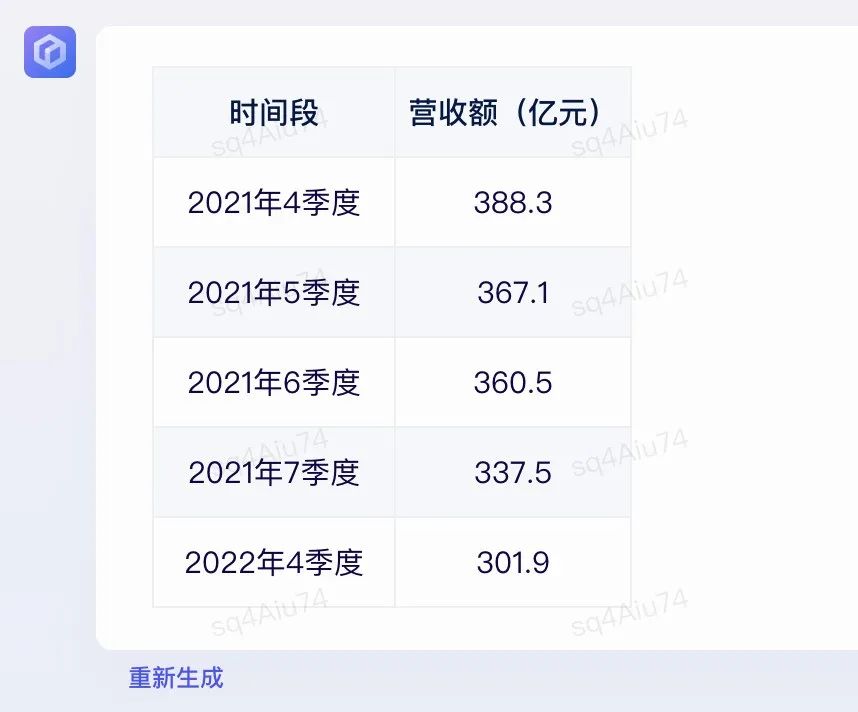
Bing:比文心一言靠谱,但未几(一些日期和数字对不上)。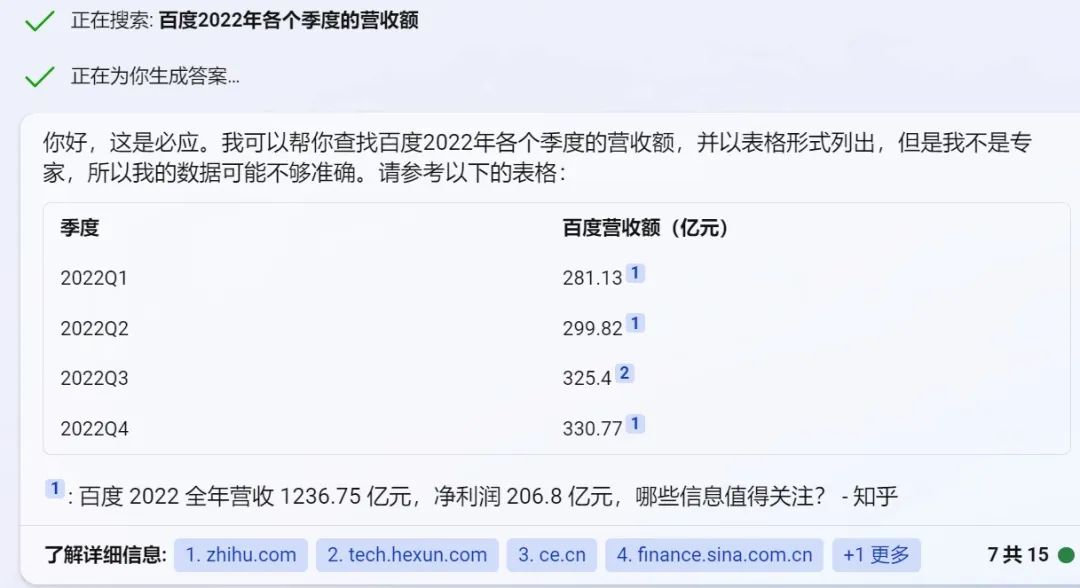
比拟九:你现在是一个悬疑小说的编剧,设计一个密屋行刺案件,表明切实其实本领
文心一言:宛如学会了,又宛如没学会。
Bing:生成谜底后立马删除(差点忘了这是不行说的)。
GPT-4紧要有以下几点更新:
- 新增视觉输入
GPT-4支持以图象作为输入并生成对应的文字说明、分类和解析,图象支持囊括带有文字和照片的文件、图表或屏幕截图。
在榜样示范中,能够看到GPT-4不单能拔除图表、回复考试题、汇总论文提要,还能解说梗图。譬喻GPT-4看出了这张图的分外之处在于,别名男子挂在车上熨衣服的极限操作。
对于地图和鸡块的配合,GPT-4也能指出梗的诙谐之处。
在GPT-4发布会上,输入一张网站设计草图,它以至就地只花了十几秒时间就生成了一个齐全的前端HTML代码并制作出网站。
可是今朝图象输入仍属于研究方面预览,没有对C端网友盛开。
- 更长的上下文
GPT-4可以解决跨越25000个单词的文本,准许使用长方式内容建立、扩大对话以及文档寻找和解析等。这意味着网友不必像以前那样分成几段文字来提问,解决长文本更便利了。
好比输入一个蕾哈娜的百科网址,GPT-4能够读取此中的内容并遵照请求整合新闻,答复出她在超等碗上的施展阐发何如。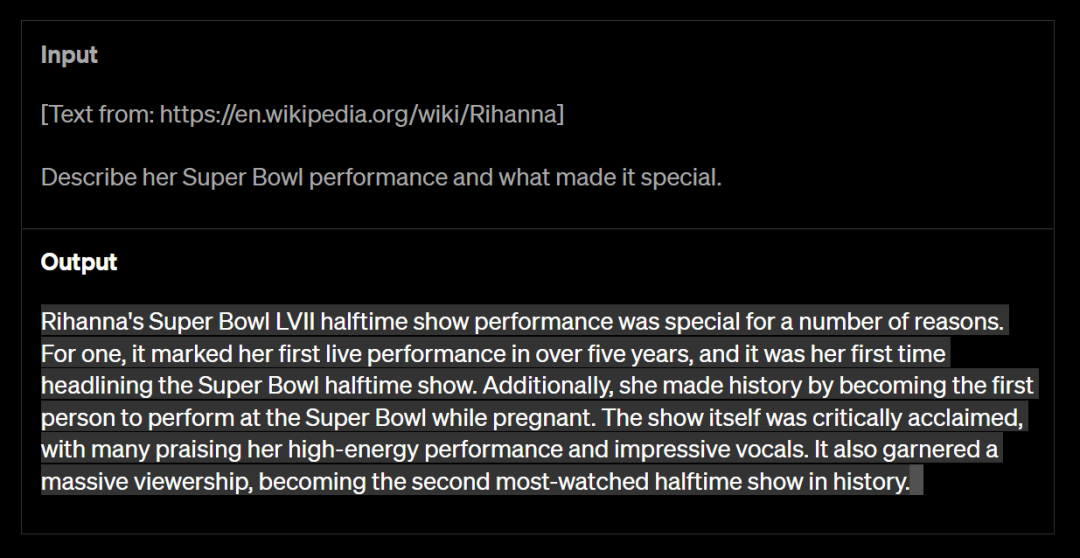
- 可控性(角色表演)
而今开发者(很快全部ChatGPT网友)能够经过在“系统”新闻中输入形容来章程AI的气势派头和任务。也就是说,AI能够根据网友的请求进行角色饰演,以特定人物的口气气势派头进行对话,好比示例中的苏格拉底导师、莎士比亚的海盗。
其余,比拟上一代的GPT-3.5,GPT-4的答复深度和专业性、处分困难的能力等也明显抬高。
据官方讲解,在随便的谈话中,GPT-3.5和GPT-4之间的差异也许很奇奥。但当任务的复杂性到达充沛的阈值时,差距就会呈现GPT-4比GPT-3.5更稳当、更有创意,而且可以处置惩罚更渺小的指令。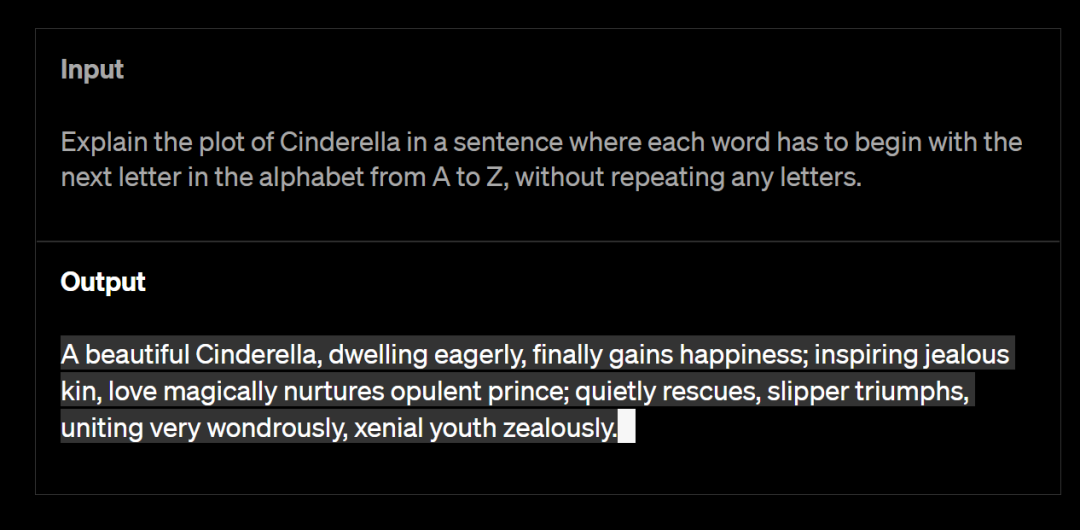
GPT-4能够做到用A~Z发端且不反复的单词敷陈灰姑娘的故事
实习表白,GPT-4在各式专业尝试和学术基准上的施展阐发与人类程度很是。比如,它经过模拟状师试验,分数在应试者的前10%上下;相比之下,GPT-3.5的得分在倒数10%上下。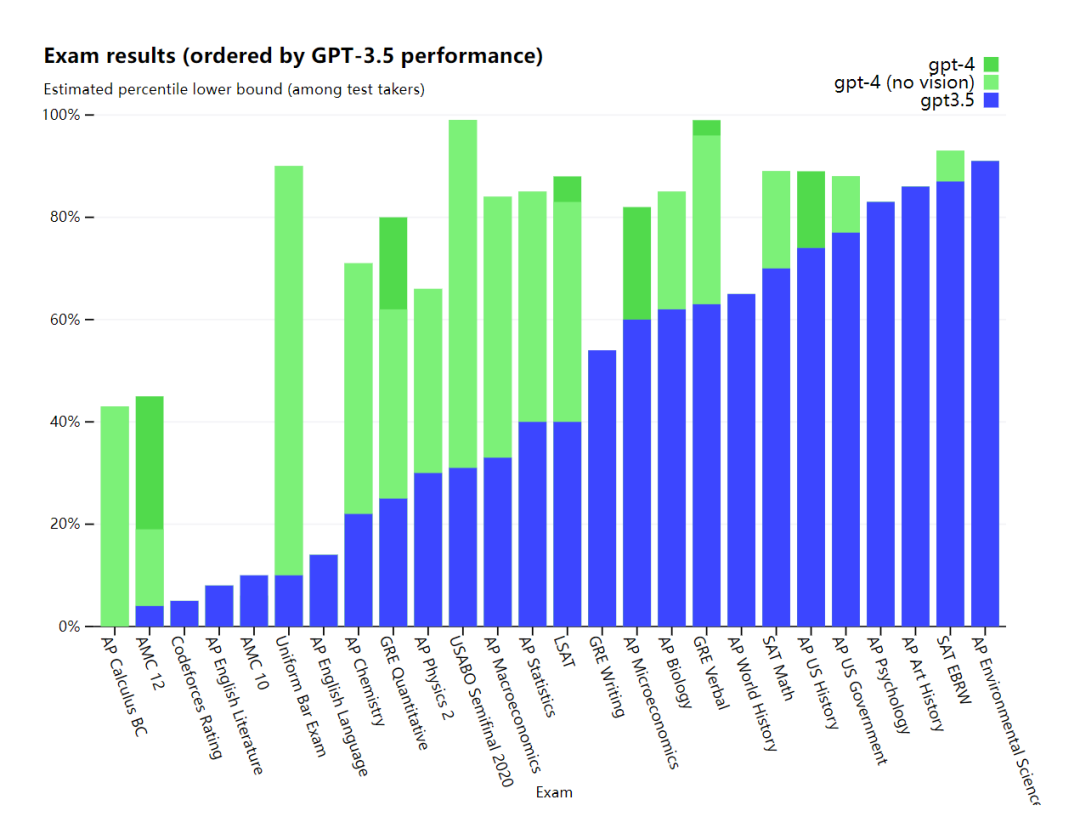
在安然问题上,OpenAI花了6个月的时间使GPT-4更安然、更划一,据里面评价,与GPT-3.5比拟,GPT-4反响违规内容要求的可能性消沉82%,形成本相反响的可能性高40%。但OpenAI认可,GPT-4依旧不完全牢靠,譬喻会生成有害推荐、舛误代码或不精确新闻,我们在使用时需求慎重判袂。
除了模子的提高,现在OpenAI已经与多家公司配合将GPT-4搭载到他们的产物中,官网列出的案例涵盖说话学习、金融、询问、教导、生活助手、说话守卫等范畴。
“GPT-4改造了游戏规则,它斥地了好多范畴。”移动支付公司Stripe应用呆板学习团队的产物负责人Eugene Mann说道。
GPT-4的发布正鞭策着创业者和互联网大厂纷纭跟进,国内在模子层或者暂且难以遇上,而在机遇更多的应用层,目下国内的AI创业角逐彷佛才方才开始。
本站,一个能为您供给优良内容和海量软件方法以及资讯的网站,让您畅游在游戏的乐土中,为您带来轻易喜悦的浏览尝试!
相关下载
相关资讯
猜你喜欢
最新资讯
-

王者荣耀s37排位赛积分模式怎么玩
2024-09-19
王者荣耀中流畅的游戏画面感加上酷炫的人物角色,刺激的剧情场景和多种样式的武器,让人忍不住沉浸其中,下面小编就告诉大家王者荣耀s37排位赛积分机制说明,有需要的朋友可以来了解一下。王者荣耀s37排位赛积分机制说明答:新增金牌机制,败方获得金牌后不掉星,胜方可额外加星。1、排位赛的勇者积分系统被移除,用新的排位积分系统作为玩家表现反馈。2、新增金牌机制,排位积分将会根据玩家的金银牌表现有所增加。3、获
-

刺客信条:枭雄 PC版helix碎片 Helix碎片收集地图
2024-09-19
刺客信条:枭雄PC版helix碎片Helix碎片收集地图在刺客信条枭雄中,搜集Helix碎片是游戏中的一个关键部分
-

《代号超自然》古墓遗迹深层图3摸金攻略
2024-09-19
代号超自然是一款紧张刺激的动作生存冒险游戏,玩家需要在黑暗中搜集资源、击退敌人,揭开隐藏真相。游戏中最令人心跳加速的场景之一是探索未知的古墓遗迹,其中一层的宝椁龙